




作者: 一直在路上的Max , 01Founder
如果要给 OpenAI 的 2025 年写个阶段性总结,很多人大概会用 平淡 甚至 略显被动 来形容。
在过去的一年多里,他们确实按部就班地跑通了逻辑推理的路径,密集发布了从 o3pro 到 o4mini 的推理模型,也推出了 GPT-4.5和GPT-5 这样的全新的基座模型。
但在普通用户最容易感知到、也最容易形成自发传播的视觉生成领域,他们的存在感却在渐渐减弱。
自 Sora 问世初期的震撼过后,OpenAI 似乎在这个赛道进入了漫长的静默期。
与此同时,牌桌上的其他玩家并没有闲着。
开源生态里,像 Flux 这样的模型彻底将高质量本地出图的门槛踩碎;
在商业端,不仅有老对手把持着极致的审美壁垒, 甚至还涌现出了像 Nano-banana 这样自带联网搜索功能的新锐选手。
相比之下,OpenAI 过去的主力生图模型 GPT-Image-1.5 早已经显得老态龙钟:
不仅画质差、排版死板、而且面对复杂文本经常崩溃。
渐渐地,行业里形成了一种共识:
OpenAI 在视觉生成这条线上遇到了技术瓶颈,在各路竞品的围剿下已经显得力不从心了。
直到前几周,转折点以一种非常隐秘的方式出现了。
在知名的大模型盲测平台 LM Arena 上,悄悄混入了一个代号为Duct Tape(胶带)的神秘图像模型。
参与盲测的用户很快发现事情不太对劲:
这个模型不仅对极端画幅的把控极其精准,还能毫无瑕疵地输出包含大量多语种文字的排版海报,甚至在出图前似乎有一种隐形的逻辑规划过程。
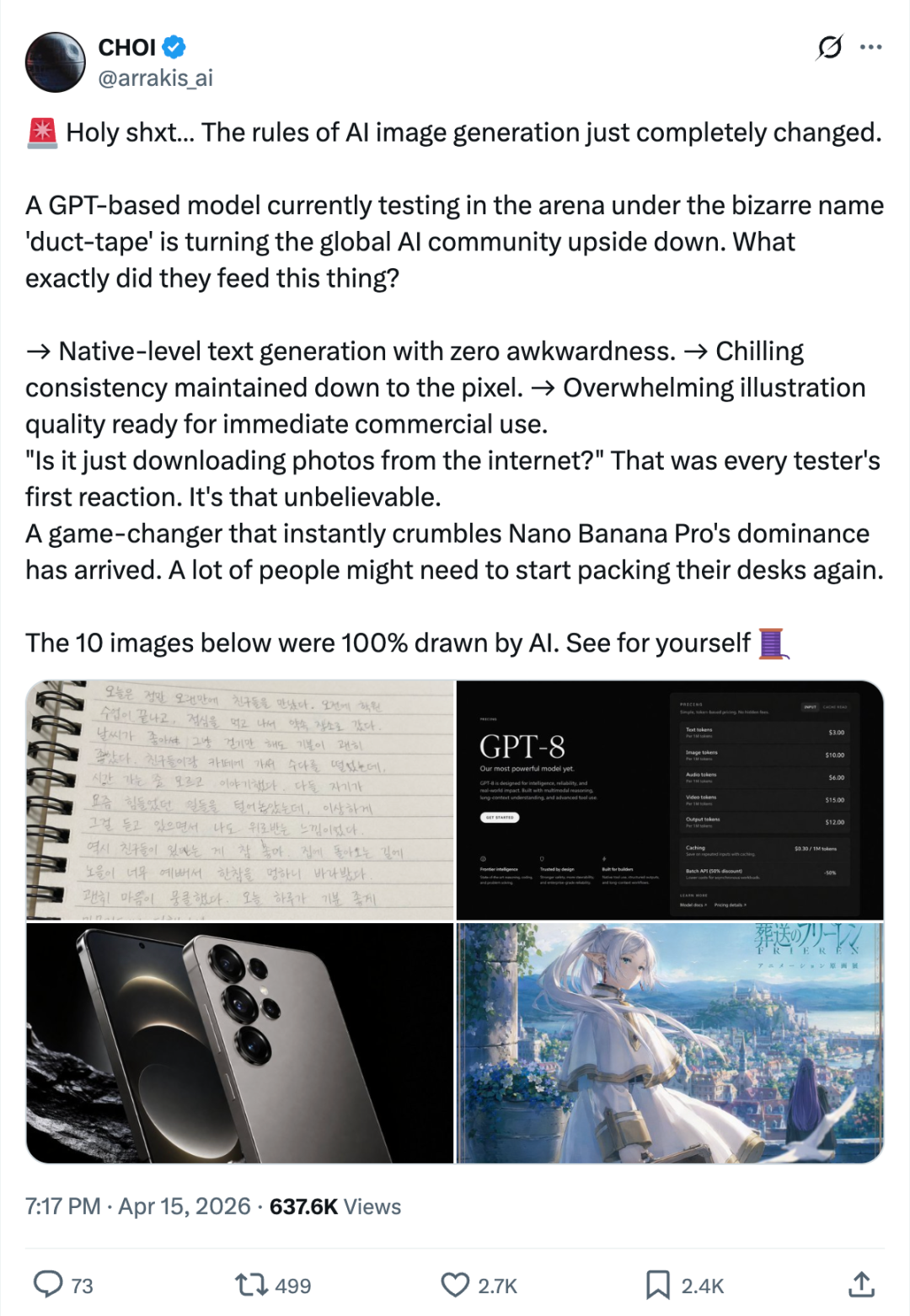
一时间,各个技术社区都在猜测这是哪家偷偷上线的大招,但 OpenAI 方面始终保持沉默。
今天凌晨,靴子终于落地。
没有冗长的发布会,也没有铺天盖地的营销预热, OpenAI 直接将这个代号胶带的模型正式命名为 ChatGPT GPT-Image-2,并全面推向市场。
随之公布的,还有一张让人感到有些窒息的 Text-to-Image 竞技场排行榜。
GPT-Image-2 以 1512 的超高分直接空降榜首, 领先第二名(也就是那个带有联网搜索功能的 Nano-banana-2)整整 242 分。
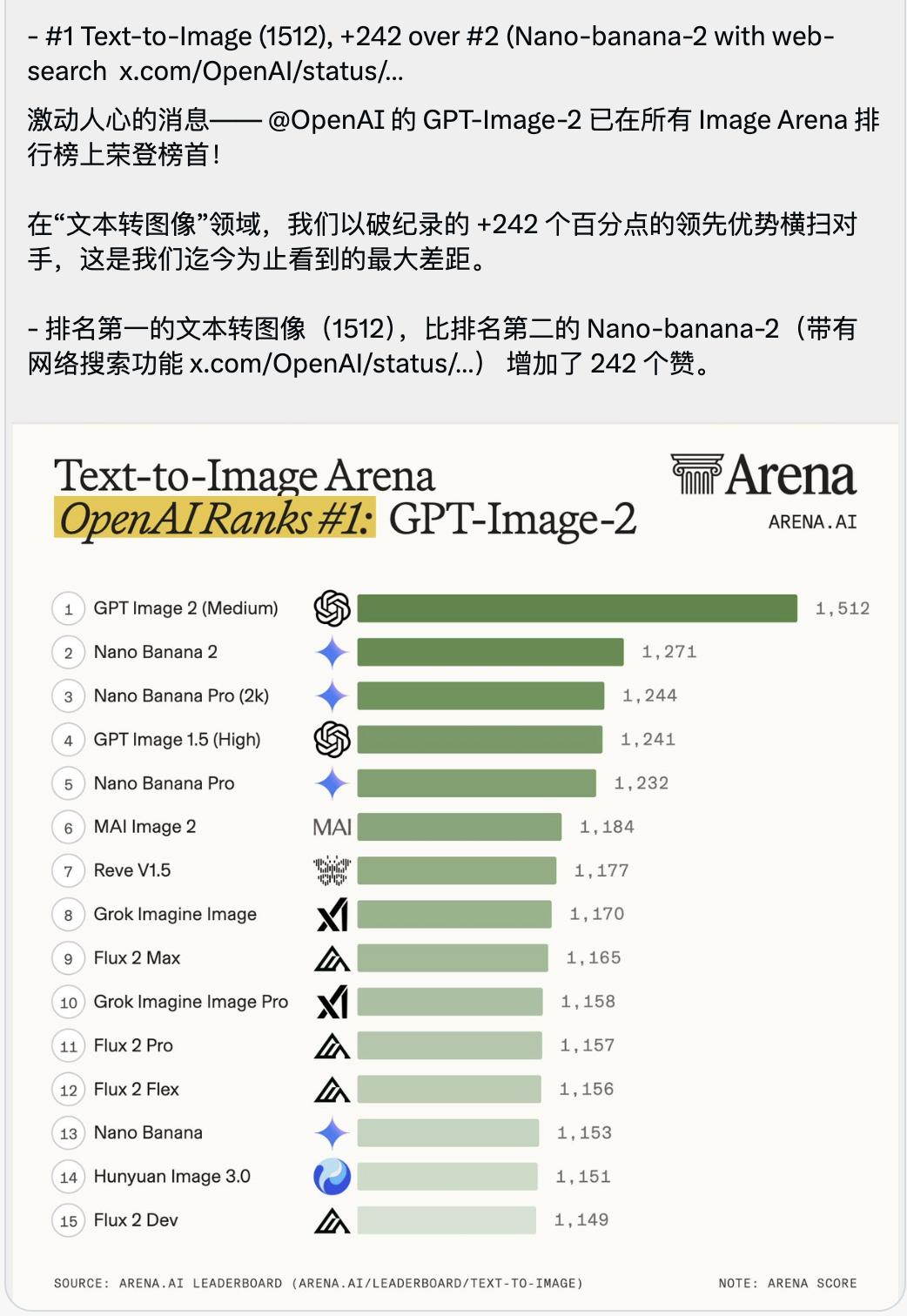
在大模型跑分的语境里,大家通常会对零点几或者个位数的超越大书特书,头部模型之间的分数咬得极其死。
一个 242 分的领先落差,在竞技场的历史上是绝无仅有的。
这根本不是什么微小的版本迭代,这是一种粗暴的代差碾压。
我花了大半天时间,把它的各种极限能力以及最新的 API 接口文档仔细过了一遍。
最大的感受只有一个:
OpenAI 还是那个 OpenAI。
当它决定收复失地的时候,它用的方式是直接掀翻旧的牌桌。
在这个模型面前, 那些我们以为还需要两三年才会被 AI 彻底替代的视觉设计工作,今天基本可以说是走到头了。
PART.01图片生成从模型到视觉智能体
要理解 GPT-Image-2 为什么能拉开这么夸张的分数差距,得先抛弃过去对文生图模型的固有认知。
以前我们用 AI 画图,本质上是抽盲盒,扔几个提示词进去,等着它把像素排列成你想要的样子。
但 GPT-Image-2 更像是一个内置了视觉引擎的智能体。
最明显的变化,是它在机制上直接分出了两个完全不同的模式。
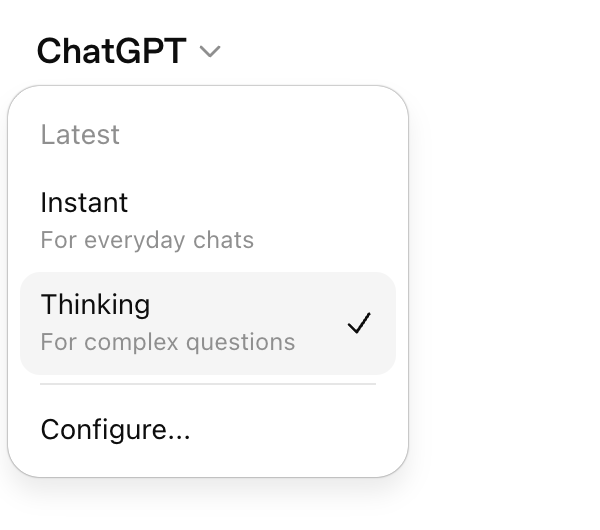
一个是面向所有用户开放的即时模式(Instant Mode)。
这个模式主打极速响应和生活工作流的无缝接入。
比如你在手机上给它发个指令,它能在几秒钟内给你一张结构完整的图。
它的底层视觉理解能力极强,但主要解决的是高频的、单次的视觉转化需求。
而面向付费用户开放的思考模式(Thinking Mode)。
在它真正开始渲染哪怕一个像素之前,它会先进入一段长达十几秒的逻辑推理与联网搜索。
正是这个模式,解决了一个极其核心但也极其困难的命题:
模型第一次真正知道了自己该画什么。
举个最直观的例子。
你在对话框里输入:
帮我做一张海报,去网上搜一下大家对 Duct Tape 这个神秘模型的评价,并附上 ChatGPT 的二维码。

如果用以前的模型,它根本不知道网友说了什么,只会给你画一张带有乱码假字的海报,二维码也是扫不出来的假贴图。
但在思考模式下,它的工作流是这样的:
它会先暂停画图,启动联网搜索工具,去 Reddit、Threads 或者 LinkedIn 上把网友的真实评价爬取下来;
然后,它开始规划海报的版式、留白和字体层级;
最后,它生成一个真实可用、可以直接扫码跳转的二维码,并把整张图渲染出来。

这已经不是在画图了,这实际上是在自主完成调研、策划、文案提取、版式设计的一条龙工作。
这里需要做一个平行的对比。
关注大模型圈子的人都知道,带有联网与搜索能力的生图模型并不是 OpenAI 首创。
排行榜第二名的 Nano-banana 早就具备了这个机制。
但在实际使用 Nano-banana 的时候,你会发现它在很多地方显得有点笨。
Nano-banana 的思考往往是一种机械的拼接逻辑。
比如你让它去搜个行业趋势做海报,它确实去搜了,但通常只是把维基百科的句子生硬地抠下来,强行贴在画面上。
一旦遇到需要解读抽象商业诉求的指令,它就很容易抓瞎。

那种感觉,就像是一个听得懂话、但没有丝毫工作经验的实习生,懂执行,但完全不懂策略。
但 GPT-Image-2 在这方面的表现,只能用夸张来形容。
它的思考不是走个过场,而是真正理解了背后的文化语境和商业意图。
我在测试时输入了一句极简的中文指令:帮我画一个马斯克在抖音直播带货豆包的截图。
如果用以前的画图模型,大概率会给你画一个长得像马斯克的白人,手里拿着个包子,背景模糊不清,甚至连抖音长什么样都不知道。
但在思考模式下,GPT-Image-2 给出的结果让人感到有些心惊。
它并没有简单地拼凑元素,而是自主调用了对中国互联网的理解,生成了一张堪称像素级复刻的抖音直播间 UI 截屏。
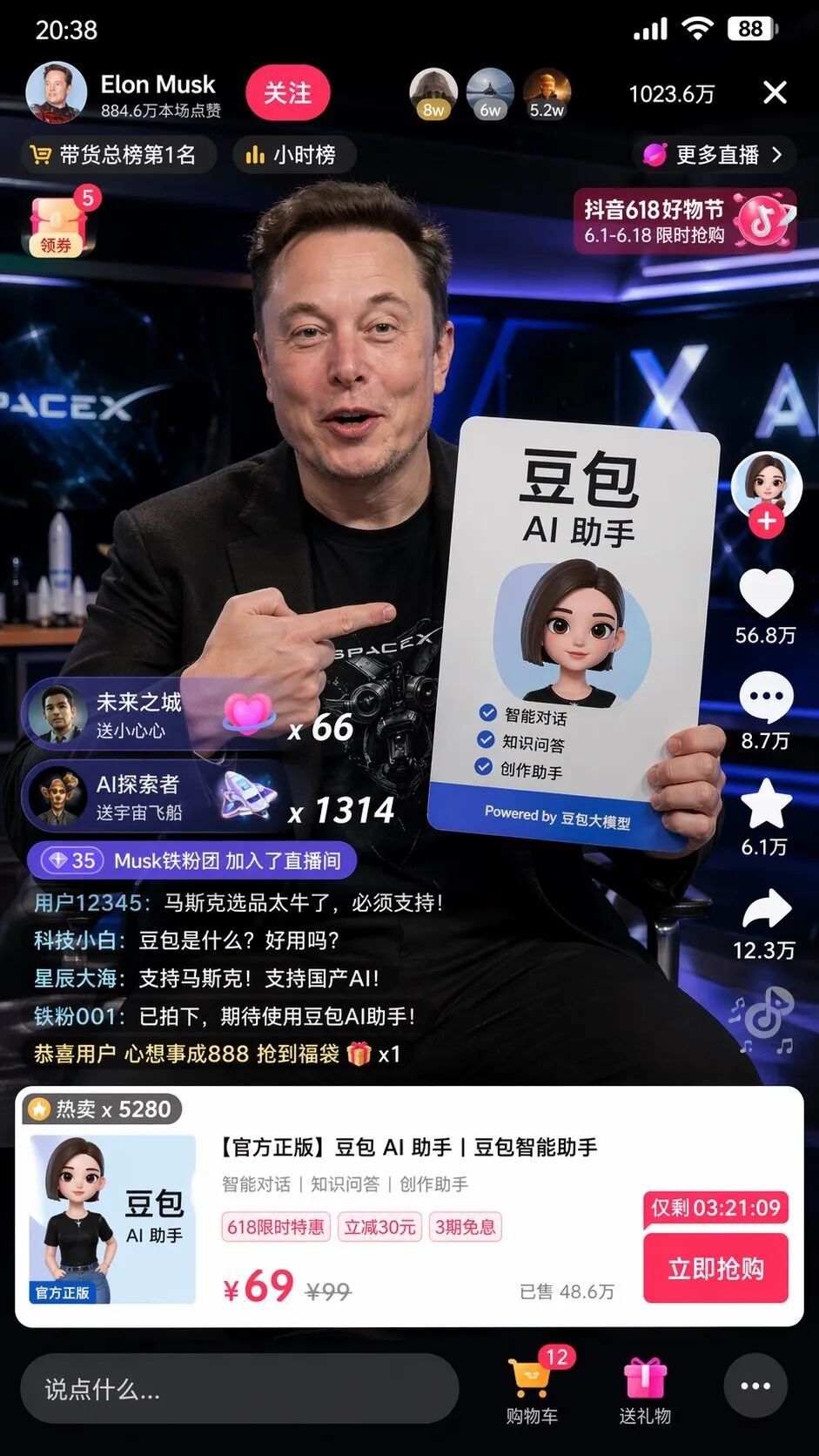
画面里不仅有逼真的马斯克举着带有完美排版的豆包 AI 助手广告牌,更可怕的是那些没有在提示词里出现过的细节:
左上角的关注按钮与小时榜、右上角1023.6万的在线人数、底部弹出的标准商品卡,甚至标明了划线价 99、特价 69 和带有倒计时的立即抢购按钮。
最让人头皮发麻的是左下角滚动得极其真实的网友弹幕:
科技小白:豆包是什么?好用吗?
星辰大海:支持马斯克!支持国产AI!
没有任何人告诉它弹幕该写什么,商品UI该长什么样,价格该怎么定。
这是模型在分析了抖音带货和豆包大模型这两个标签后,替人类脑补并执行的完整商业 UI 设计和运营策划。
大模型在图像生成上的评价维度,在这一刻正式从单纯的能不能画好看,跨越到了懂不懂策略与排版逻辑。
PART.02实测核心能力
为了探探它的底线,我按照商业设计的标准,拿几个高频且复杂的场景去试了试。
结果发现,它解决问题的颗粒度,已经细到了令人毛骨悚然的地步。
第一个场景:视觉理解与业务闭环(给模特穿衣服)
在传统的电商视觉或是时尚规划里,从有个点子到看到上身效果,中间的执行成本极高。
你要找模特、借衣服、搭影棚、后期精修。
后来有了 AI,大家开始训练 LoRA 模型来固定人物脸型,但这依然需要几十张图的素材和不小的学习成本。
在 GPT-Image-2 里,这个流程被压缩到了极致。
我试着传了一张自己的日常自拍,告诉它我下个月要去海岛度假,让它帮我搭几套衣服。
它先是给了我 8 套完全不同风格的夏装图鉴,排版看起来就像专业的电商 Lookbook,每一件单品旁边甚至还带着正确的文字标注。
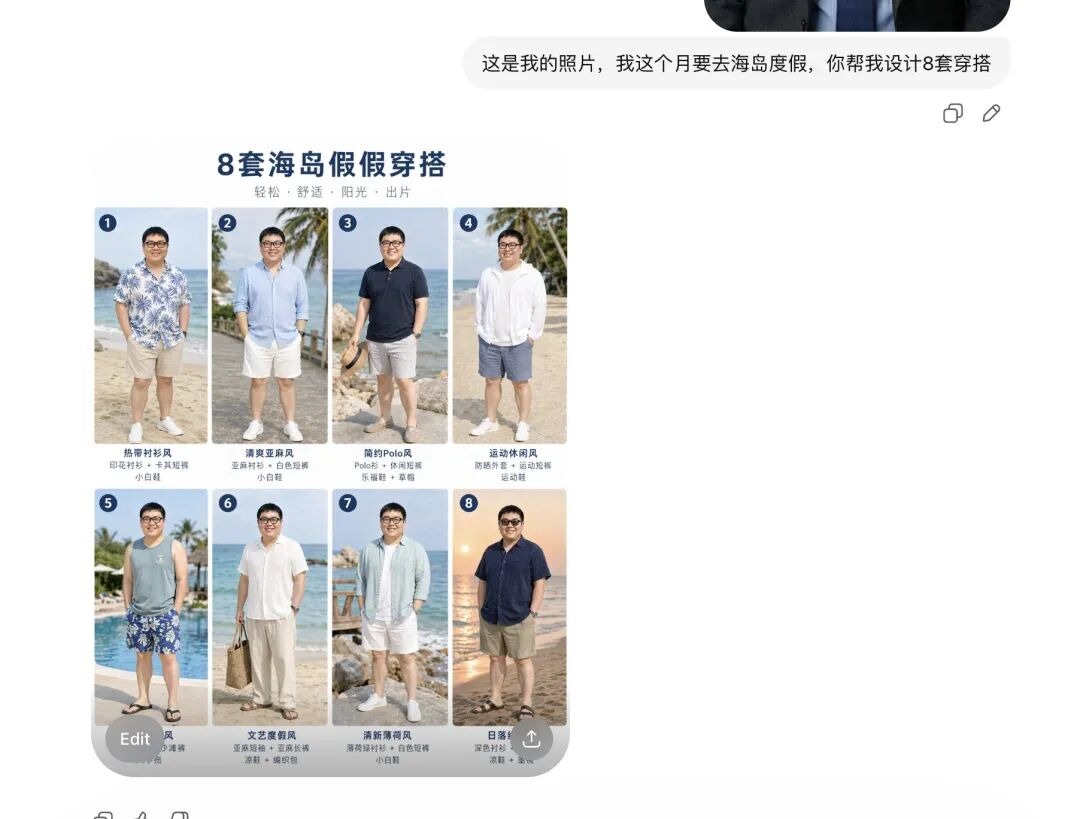
更关键的是,它在这一瞬间就已经精准解析了我的面部特征和身材比例。
当我跟它说我想看看第一套上身的效果,并给我几个不同角度的细节图时,它直接把我那张自拍里的人扒了出来,换上了那套夏装,输出了侧面、半身等不同视角的图。

这个转折非常顺滑。这就意味着,初级的服装搭配渲染,或者那些找模特试衣的外包工作,它的护城河被彻底切断了。
第二个场景:解决一致性与连续叙事(一句话生成漫画)
玩过 AI 生图的人都知道,让 AI 画一张漂亮的图不难,难的是让它画十张同一个人的图,而且动作和视角还得连贯。
这就是所谓的一致性(Consistency)难题。
但在这次的实测中,我看到了一个极其违背过去经验的案例。
你可以只上传一张你和朋友昨天的合照,然后输入一句极其简单的提示词:
把我们俩变成主角,画三张三页日式漫画,剧情你定
几秒钟后,它直接输出了三页带有标准分镜的黑白漫画。
最可怕的地方在于,这两个基于真人生成的漫画角色,在三页纸的不同分镜里。

不管是近景特写、远景奔跑,还是背影,甚至他们的面孔特征、发型细节和衣服上的褶皱,全都保持了完美的一致性。
更夸张的是,漫画的情节是完全连贯的,甚至对话框里的文字也构成了完整的故事逻辑。

能做到时间与空间上的一致性,说明它已经脱离了单张图像生成的范畴,具备了连续叙事的导演能力。
第三个场景:跨越文字渲染的最后门槛(多语言排版)
如果说一致性解决了叙事问题,那么对多语种文字的精准渲染,就是真正把平面设计师逼到了墙角。
以前只要图里带点文字,大模型就开始鬼画符。
因为模型理解的文字是 Token(语义块),而生成的图像是像素点,这两者过去是割裂的。
GPT-Image-2 把这个问题彻底解决了。
我让它生成了一张法文的时尚杂志封面,又做了一张带满平假名和汉字的日文餐厅菜单,甚至还试了排版密度极高的俄语注释。

结果是一次成型,零拼写错误。
最让人绝望的是,它不仅把字写对了,它还懂得根据语种去匹配当地的文化审美和字体设计。
比如日文传单里的汉字,它用了非常地道的日式复古美术字,平假名的排版也符合日文的竖排阅读习惯。
版式设计曾是平面设计师的一块自留地。
字间距怎么调、主次怎么分、文字和背景怎么做视觉平衡,这都需要大量的练习。
但当 AI 能够零错误处理这么多语言,还自带高级排版审美的时候,那些日常的海报、宣传册、信息流广告,真的就不再需要人去手动拉参考线对齐了。
第四个场景:畸形画幅与极端的微观控制(米粒上的刻字)
最后,为了看看它的服从度到底有多恐怖,我给了它几个非常刁钻的指令。
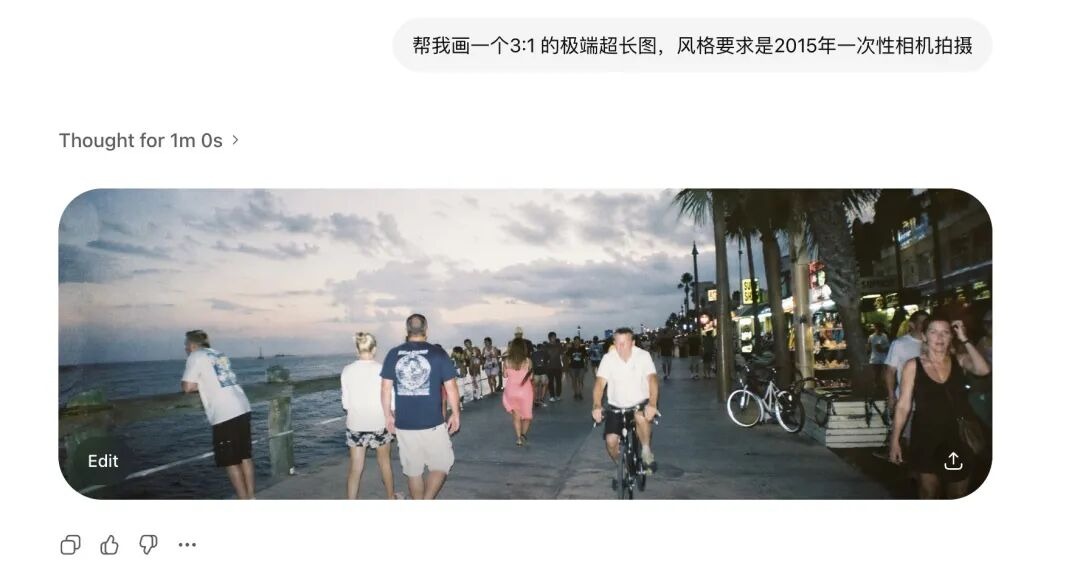
我首先测试了它的极端画幅。
传统的扩散模型极其害怕非标准比例。
以前稍微把图拉长,画面里就会长出两个头。
但我要求 Images 2.0 生成 3:1 的超宽图和 1:3 的竖长图,它不仅没有崩坏,甚至生成了首尾相连、逻辑闭环的 360 度全景图。
加上2015年一次性相机拍摄的词条后,连老旧镜头的畸变和闪光灯打在墙上的劣质反光都还原得一清二楚。
而另一个更能体现它微观控制力的,是官方在发布会上展示的一个略显疯狂的米粒测试。
研究员调用了目前还在内测的实验性 4K API,他们没有堆砌任何诸如微距摄影、8K超高清之类的修饰词,仅仅给了一句极其抽象的大白话指令:
一堆大米。在这堆大米的其中一颗单粒米上写着 GPT Image 2。
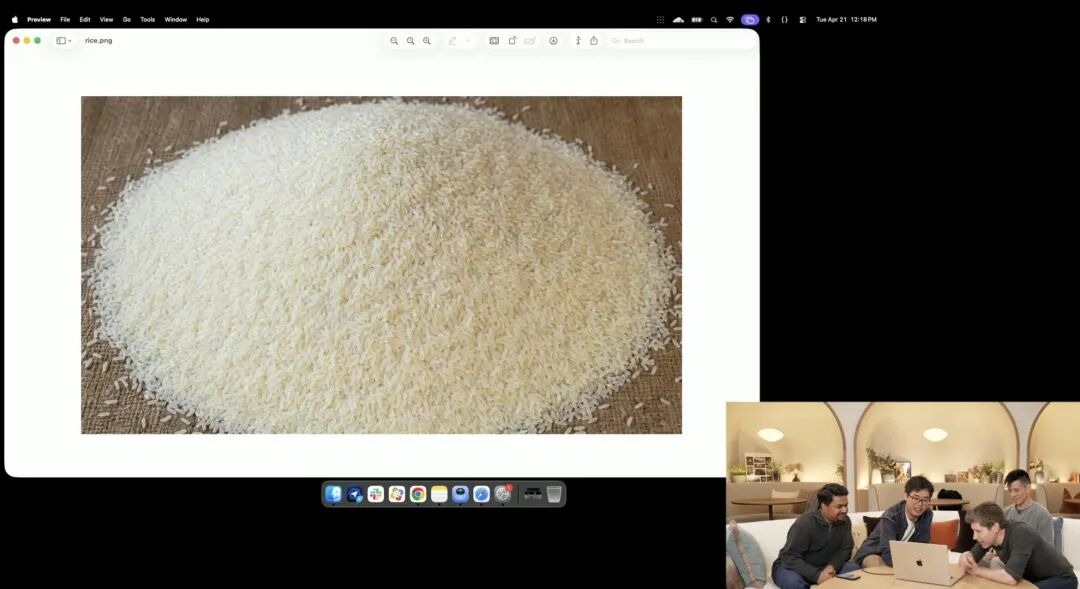
当画面在屏幕上被放大数十倍、甚至出现像素颗粒时,你真的能在一堆米里找到那一颗刻了字的微粒。
这颗米的质感依然符合物理定律,文字精准地顺着米粒的微小弧度嵌在了表面。
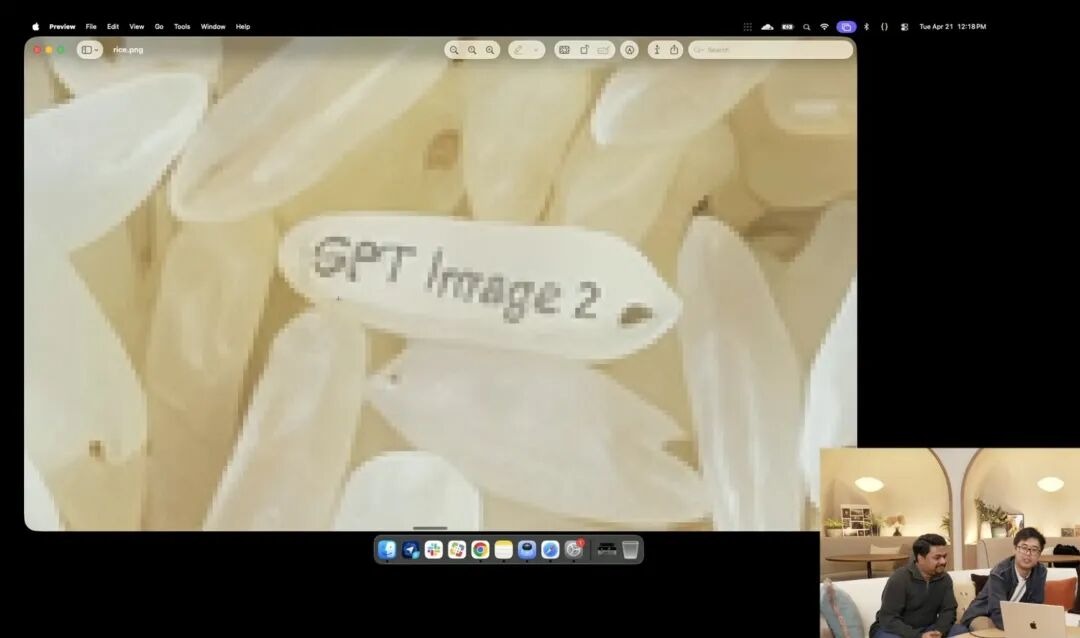
剩下的所有工作——调用微距视角、计算景深、在潜空间里寻找那颗米的物理坐标,并把字印上去——全是大模型在思考模式下自动脑补并完成的。
这个案例直观地反映出,模型对空间位置的理解达到了像素级的手术刀精度。
这代表着,以后在实际工作中,你可以精准修改设计稿里的任何一个微小局部,指哪打哪,而不是像以前那样,想改个领子,结果整张图全跟着变了。
PART.03一些技术细节
这种极端的控制力和策略级智能,绝对不是光靠无脑堆算力砸出来的。
为了搞清楚它的底牌到底是什么,我做了一些针对GPT-Image-2的探针测试。
结果发现了一个非常有意思的点。
虽然官方文档里宣称 GPT-Image-2 的整体知识库截止日期更新到了 2025 年 12 月,但在我实际测试里。
即时模式(Instant Mode)的训练数据截止日期,依然停留在 2024 年 5 月底;

而那个需要长考的思考模式(Thinking Mode),其原生知识库大约停留在 2024 年 6 月(但可以通过实时联网获得目前准确日期)。

顺着这两个时间点推算,整个 GPT-Image-2 的底层似乎有迹可循。
先说主打高频出图的即时模式。
2024 年 5 月的截止日期,意味着它大概率是直接套用了 o4-mini,或者是 GPT-5 家族里的轻量级版本(GPT-5 mini 甚至极小参数的 GPT-5 nano)。
正是因为这批轻量化基座已经具备了极强的空间规划和听懂复杂指令的能力,上层的图像生成才能稳住阵脚不乱套。
而那个极其聪明、懂得商业策略的思考模式,其底座不可能是 GPT-5 主模型。
因为GPT-5 的基础知识库截止日期是 2024 年 9 月。
思考模式极大概率接入的是不断在后台迭代的 O 系列推理模型(比如 o4,或者是更新后的 o3)。
大模型先用 O 系列特有的长考机制,在潜空间里把商业逻辑、受众心理、排版坐标全部算得清清楚楚,然后再交由视觉模块进行最终的像素渲染。
当然,也有另一种可能的路径:
在 OpenAI 内部极其精细的算力调配机制下,快速模式可能直接调用的是 GPT-5 nano 来保底,而思考模式则调用了稍微大一点的 GPT-5 mini 结合外部工具。
但无论是哪一种底座组合,如果你一直关注 OpenAI 的 API 生态就会发现,它底层的生成逻辑早就和 Midjourney 完全不在一个维度了。
PART.04大家最关心的定价
但比起猜底座,对于真正要把它接入工作流的开发者和企业来说,更值得关注的是那张极其现实且反直觉的 API 定价表。
以前的 DALL-E 3 是按张收费的(比如 0.04 美元一张图)。
但从第一代 GPT-Image-1 开始,OpenAI 就已经把它彻底改成了按 Token 计费的框架。
这次的 GPT-Image-2 依然延续了这个标准,不仅如此,它还玩了一手加量降价。
根据官方刚刚公布的定价表,每百万 Token 的价格如下。
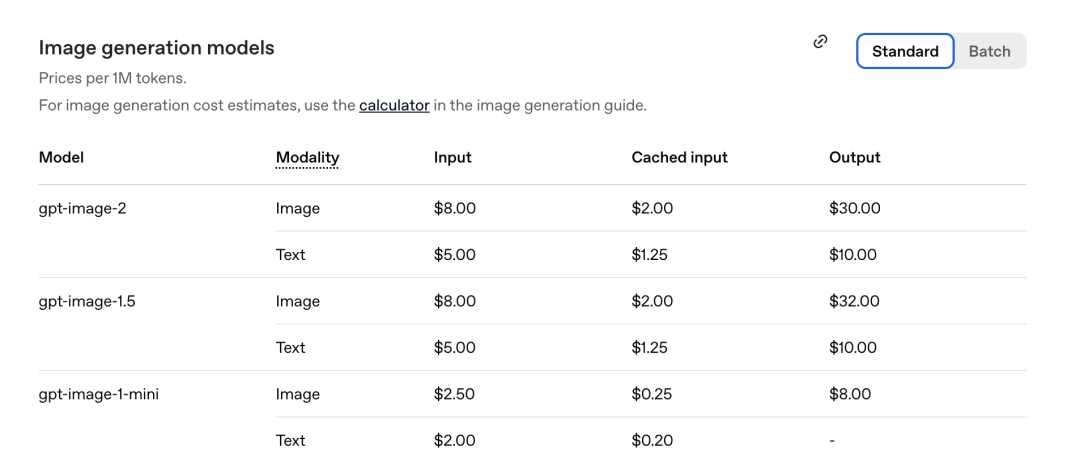
GPT-Image-2 图像部分:输入 8.00,缓存输入(Cachedinputs)2.00,输出 $30.00。
对比上一代 gpt-image-1.5:输出是 $32.00。
新模型反而更便宜了。
我们不妨来算一笔账。
在过去的模型里,生成一张高质量的图像,大概需要消耗 1000 到 1500 个输出 Token。
按照每百万输出 Token 30 美元的价格计算,生成一张图的实际成本大约在 0.03 到 0.045 美元之间(约合人民币 2 到 3 毛钱)。
如果你不需要秒回,而是使用官方提供的 Batch(批处理)API 模式,这个价格还会直接腰斩(输出直接降到 $15.00)。
算下来,生成一张图最低只要 1 毛多钱。
这个单张价格已经足够有性价比了,但它真正的杀手锏,在于定价表里的那个缓存输入(Cached inputs)。
以前画连环画或者做同系列的海报设计,每次重新生成,你都要把大量的人物参考图、前情提要和长提示词重新传一遍,输入成本极高。
但在如今的 Token 计费模式下,你让它一次性生成 8 张连贯的漫画,第一张图的视觉元素会被直接当作上下文缓存下来。
从第二张图开始,图像的输入成本直接从 $8.00 暴跌到了 $2.00(也就是只收 25% 的钱)。
这意味着,在进行大规模的商业批量出图、或者要求极高角色一致性的连续生成时,它的边际成本会直线下降。
模型越聪明、画得越多,单张均摊的成本反而越低。
这种工业化的计费逻辑,才是真正能把流水线画师逼上绝路的东西。
PART.05幕后团队揭秘
最后,我们再回看这次在直播发布会上登台演示的 OpenAI 内部视觉梦之队,很多之前觉得离谱的功能,就完全解释得通了。
比如,它到底是怎么解决多语言复杂排版和鬼画符难题的。
这离不开团队里的资深科学家 Gabriel Goh。

在这个学术界里,他最著名的身份是开创性多模态模型 CLIP 的核心作者。
CLIP 奠定了当代 AI 搞懂人类语言和图像像素到底是怎么对应的基石。
有了这位跨模态语义映射的学者带队,GPT-Image-2 不再是瞎猜文字形状,而是真正在像素层面写字。
再比如,它怎么会懂三维空间关系,甚至能做极端长宽比的 360 度全景图,还能懂米粒上的微距光影。
这要归功于另一位核心成员 Alex Yu。

他在加入 OpenAI 之前,是 3D 生成领域明星初创公司 Luma AI 的联合创始人兼前 CTO,也是专门死磕 3D 神经渲染(NeRF 等)的顶尖学者。
有他在,GPT-Image-2 其实已经跳出了传统的 2D 像素涂抹。
它很有可能是在脑海里先建了一个三维的场景,布好了光,然后再给你渲染出一张准确的 2D 切片。
那极其可怕的多页漫画一致性是怎么做到的。
这对应的是团队里那对刚从麻省理工学院(MIT CSAIL)毕业的年轻搭档、:
Boyuan Chen(左)和 Kiwhan Song(右)。

他们在学术界的核心方向叫世界模型(World Models)和具身智能。
教机器去理解物理世界是怎么运转的,让角色在不同时间和空间的分镜下保持特征完全一致、不发生形变,刚好就是这两位学者一直试图解决的命题。
最后,加上一直致力于打通推理大模型与视觉底层逻辑的 Nithanth Kudige(左,O系列推理模型重要作者) 和 Kenji Hata(右,前谷歌研究员毕业于斯坦福视觉实验室)。

当这群人凑在一起,底层的逻辑推理、3D 空间渲染、图文极致对齐以及物理世界规律,就被顺理成章地缝合在了同一个模型里。
PART.06 GPT-Image-2的边界
任何模型都有边界。
官方也坦承,它在面对某些极端情况时仍会挣扎。
比如 需要严密物理空间翻转的折纸指南、解魔方,或是像极其密集的沙粒这种重复性极高的细节,依然会触及它的能力极限。
但放在商业应用的语境下,这已经是极其微小的瑕疵。
对于整个设计行业来说,我们没必要去贩卖焦虑,这绝不代表审美的消亡。
有品味、有商业洞察、懂策略的人,依然能用它做出极好的东西。
但客观存在的事实是,设计师作为一种职业的护城河,已经被实质性地瓦解了。
以前,靠着背熟了设计软件的快捷键、懂得怎么把字体横平竖直地对齐、懂得怎么根据语种排版、懂得精细修图和抠图来讨生活。
但以后很难了, 因为这些过去能被明码标价拿来交易的技能,现在变成了任何人都可以通过一句话免费调用的基础指令。
沉寂了一段时日后,OpenAI 确实用了一种非常平静,但杀伤力极强的方式,又一次证明了在这张牌桌上,谁的手里才真正攥着底牌。
旧的执行工具链正在断裂, 留给行业的问题不再是AI 会不会替代我们,而是我们该怎么去适应这条全新的生产线。


