作者 | ZeR0 骏达,智东西
编辑 | 漠影
芯东西拉斯维加斯1月5日报道,刚刚,英伟达创始人兼CEO黄仁勋在国际消费电子展CES 2026上发表2026年首场主题演讲。黄仁勋一如既往穿着皮衣,在1.5小时内连宣8项重要发布,从芯片、机架到网络设计,对整个全新代际平台进行了深入介绍。

在加速计算和AI基础设施领域,英伟达发布NVIDIA Vera Rubin POD AI超级计算机、NVIDIA Spectrum-X以太网共封装光学器件、NVIDIA推理上下文内存存储平台、基于DGX Vera Rubin NVL72的NVIDIA DGX SuperPOD。

NVIDIA Vera Rubin POD采用英伟达6大自研芯片,涵盖CPU、GPU、Scale-up、Scale-out、存储与处理能力,所有部分均为协同设计,可满足先进模型需求并降低计算成本。
其中,Vera CPU采用定制Olympus核心架构,Rubin GPU引入Transformer引擎后NBFP4推理性能高达50PFLOPS,每GPU NVLink带宽快至3.6TB/s,支持第三代通用机密计算(第一个机架级TEE),实现CPU与GPU跨域的完整可信执行环境。

这些芯片均已回片,英伟达已对整个NVIDIA Vera Rubin NVL72系统进行验证,合作伙伴也已开始运行其内部集成的AI模型和算法,整个生态系统都在为Vera Rubin做部署准备。
其他发布中,NVIDIA Spectrum-X以太网共封装光学器件显著优化了电源效率和应用正常运行时间;NVIDIA推理上下文内存存储平台重新定义了存储堆栈,以减少重复计算并提升推理效率;基于DGX Vera Rubin NVL72的NVIDIA DGX SuperPOD将大型MoE模型的token成本降低至1/10。

开放模型方面,英伟达宣布扩展开源模型全家桶,发布新的模型、数据集和库,包括NVIDIA Nemotron开源模型系列新增Agentic RAG模型、安全模型、语音模型,还发布了适用于所有类型机器人的全新开放模型。不过,黄仁勋并未在演讲中详细介绍。
物理AI方面, 物理AI的ChatGPT时刻已经到来 ,英伟达全栈技术使全球生态系统能通过AI驱动的机器人技术改变行业;英伟达广泛的AI工具库,包括全新Alpamayo开源模型组合,使全球交通行业能快速实现安全的L4驾驶;NVIDIA DRIVE自动驾驶平台现已投入生产,搭载于所有全新梅赛德斯-奔驰CLA,用于L2++ AI定义的驾驶。

01.全新AI超级计算机:6款自研芯片,单机架算力达3.6EFLOPS
黄仁勋认为,每10到15年,计算机行业就会迎来一次全面的重塑,但这次,两个平台变革同时发生,从CPU到GPU,从“编程软件”到“训练软件”,加速计算与AI重构了整个计算堆栈。过去十年价值10万亿美元的计算产业,正在经历一场现代化改造。
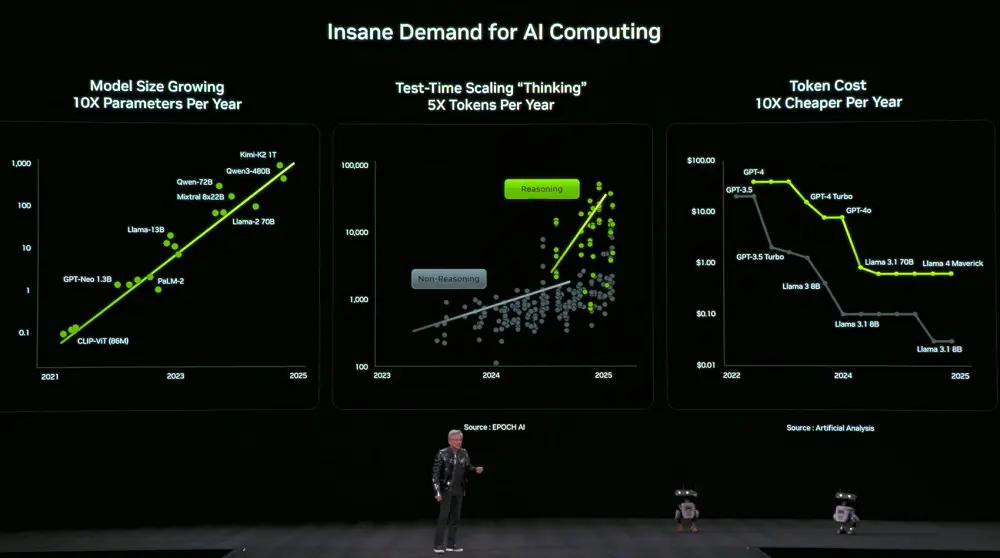
与此同时,对算力的需求也急剧飙升。模型的尺寸每年增长10倍,模型用于思考的token数量每年增长5倍,而每个token的价格每年降低10倍。
为了应对这一需求,英伟达决定每年都发布新的计算硬件。黄仁勋透露,目前Vera Rubin也已经全面开启生产。
英伟达全新AI超级计算机NVIDIA Vera Rubin POD采用了6款自研芯片:Vera CPU、Rubin GPU、NVLink 6 Switch、ConnectX-9(CX9)智能网卡、BlueField-4 DPU、Spectrum-X 102.4T CPO。
Vera CPU: 为数据移动和智能体处理而设计,拥有88个英伟达定制Olympus核心、176线程的英伟达空间多线程,1.8TB/sNVLink-C2C支持CPU:GPU统一内存,系统内存达1.5TB(是Grace CPU的3倍),SOCAMM LPDDR5X内存带宽为1.2TB/s,并支持机架级机密计算,数据处理性能翻倍提升。

Rubin GPU: 引入Transformer引擎,NVFP4推理性能高达50PFLOPS,是Blackwell GPU的5倍,向后兼容,在保持推理精度的同时提升BF16/FP4级别的性能;NVFP4训练性能达到35PFLOPS,是Blackwell的3.5倍。
Rubin也是首个支持HBM4的平台,HBM4带宽达22TB/s,是上一代的2.8倍,能够为苛刻的MoE模型和AI工作负载提供所需性能。

NVLink 6 Switch: 单lane速率提升至400Gbps,采用SerDes技术实现高速信号传输;每颗GPU可实现3.6TB/s的全互连通信带宽,是上一代的2倍,总带宽为28.8TB/s,FP8精度下in-network计算性能达到14.4TFLOPS,支持100%液冷。

NVIDIA ConnectX-9 SuperNIC: 每颗GPU提供1.6Tb/s带宽,针对大规模AI进行了优化,具备完全软件定义、可编程、加速的数据路径。

NVIDIA BlueField-4: 800Gbps DPU,用于智能网卡和存储处理器,配备64核Grace CPU,结合ConnectX-9 SuperNIC,用于卸载网络与存储相关的计算任务,同时增强了网络安全能力,计算性能是上一代的6倍,内存带宽达3倍,GPU访问数据存储的速度提升至2倍。

NVIDIA Vera Rubin NVL72: 在系统层面将上述所有组件整合成单机架处理系统,拥有2万亿颗晶体管,NVFP4推理性能达3.6EFLOPS,NVFP4训练性能达2.5EFLOPS。
该系统LPDDR5X内存容量达54TB,是上一代的2.5倍;总HBM4内存达20.7TB,是上一代的1.5倍;HBM4带宽是1.6PB/s,是上一代的2.8倍;总纵向扩展带宽达到260TB/s,超过全球互联网的总带宽规模。

该系统基于第三代MGX机架设计,计算托盘采用模块化、无主机、无缆化、无风扇设计,使组装和维护速度比GB200快18倍。原本需要2小时的组装工作,现在只需5分钟左右,而原本系统使用约80%的液冷,目前已经100%使用液冷。单一系统本身就重达2吨,加上水冷液后能达到2.5吨。

NVLink Switch托盘颗实现零停机维护与容错,在托盘被移除或部分部署时机架仍可运行。第二代RAS引擎可进行零停机运行状况检查。
这些特性提升了系统运行时间与吞吐率,进一步降低训练与推理成本,满足数据中心对高可靠性、高可维护性的要求。
已有超过80家MGX合作伙伴准备好支持Rubin NVL72在超大规模网络中的部署。
02.三大新品爆改AI推理效率:新CPO器件、新上下文存储层、新DGX SuperPOD
同时,英伟达发布了3款重要新品:NVIDIA Spectrum-X以太网共封装光学器件、NVIDIA推理上下文内存存储平台、基于DGX Vera Rubin NVL72的NVIDIA DGX SuperPOD。
1、NVIDIA Spectrum-X以太网共封装光学器件
NVIDIA Spectrum-X以太网共封装光学器件基于Spectrum-X架构,采用2颗芯片设计,采用200Gbps SerDes,每颗ASIC颗可提供102.4Tb/s带宽。
该交换平台包括一个512端口高密度系统,以及一个128端口紧凑系统,每个端口的速率均为800Gb/s。

CPO(共封装光学)交换系统可实现5倍的能效提升、10倍的可靠性提升、5倍的应用程序正常运行时间提升。
这意味着每天可以处理更多token,从而进一步降低数据中心的总拥有成本(TCO)。
2、NVIDIA推理上下文内存存储平台
NVIDIA推理上下文内存存储平台是一个POD级AI原生存储基础设施,用于存储KV Cache,基于BlueField-4与Spectrum-X Ethernet加速,与NVIDIA Dynamo和NVLink紧密耦合,实现内存、存储、网络之间的协同上下文调度。
该平台将上下文作为一等数据类型处理,可实现5倍的推理性能、5倍的更优能效。

这对改进多轮对话、RAG、Agentic多步推理等长上下文应用至关重要,这些工作负载高度依赖上下文在整个系统中被高效存储、复用与共享的能力。
AI正在从聊天机器人演进为Agentic AI(智能体),会推理、调用工具并长期维护状态,上下文窗口已扩展到数百万个token。这些上下文保存在KV Cache中,每一步都重新计算会浪费GPU时间并带来巨大延迟,因此需要存储。
但GPU显存虽快却稀缺,传统网络存储对短期上下文而言效率过低。AI推理瓶颈正从计算转向上下文存储。所以需要一个介于GPU与存储之间、专为推理优化的新型内存层。

这一层不再是事后补丁,而必须与网络存储协同设计,以最低的开销移动上下文数据。
作为一种新型存储层级,NVIDIA推理上下文内存存储平台并不直接存在于主机系统中,而是通过BlueField-4连接到计算设备之外。其关键优势在于,可以更高效地扩展存储池规模,从而避免重复计算KV Cache。
英伟达正与存储合作伙伴紧密合作,将NVIDIA推理上下文内存存储平台引入Rubin平台,使客户能够将其作为完整集成AI基础设施的一部分进行部署。
3、基于Vera Rubin构建的NVIDIA DGX SuperPOD
在系统层面,NVIDIA DGX SuperPOD作为大规模AI工厂部署蓝图,采用8套DGX Vera Rubin NVL72系统,用NVLink 6纵向扩展网络,用Spectrum-X Ethernet横向扩展网络,内置NVIDIA推理上下文内存存储平台,并经过工程化验证。
整个系统由NVIDIA Mission Control软件管理,实现极致效率。客户可将其作为交钥匙平台部署,用更少GPU完成训练与推理任务。
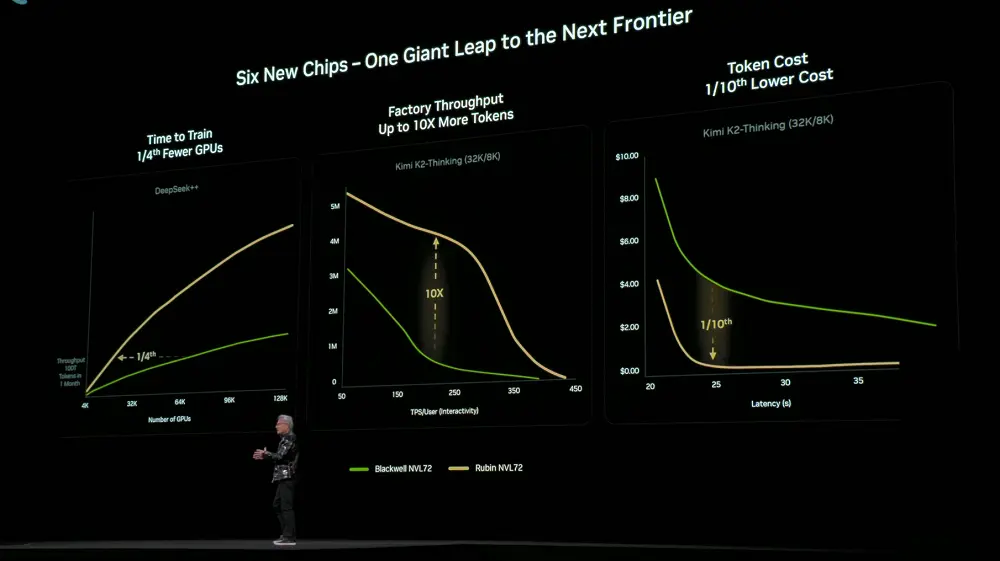
由于在6款芯片、托盘、机架、Pod、数据中心与软件层面实现了极致协同设计,Rubin平台在训练与推理成本上实现了大幅下降。与上一代Blackwell相比,训练相同规模的MoE模型,仅需1/4的GPU数量;在相同延迟下,大型MoE模型的token成本降低至1/10。
采用DGX Rubin NVL8系统的NVIDIA DGX SuperPOD也一并发布。
借助Vera Rubin架构,英伟达正与合作伙伴和客户一起,构建世界上规模最大、最先进、成本最低的AI系统,加速AI的主流化落地。

Rubin基础设施将于今年下半年通过CSP与系统集成商提供,微软等将成为首批部署者。
03.开放模型宇宙再扩展:新模型、数据、开源生态的重要贡献者
在软件与模型层面,英伟达继续加大开源投入。
OpenRouter等主流开发平台显示,过去一年,AI模型使用量增长20倍,其中约1/4的token来自开源模型。

2025年,英伟达是Hugging Face上开源模型、数据和配方的最大贡献者,发布了650个开源模型和250个开源数据集。

英伟达的开源模型在多项排行榜中名列前茅。开发者不仅可以使用这些开源模型,还可以从中学习、持续训练、扩展数据集,并使用开源工具和文档化技术来构建AI系统。

受到Perplexity的启发,黄仁勋观察到,Agents应该是多模型、多云和混合云的,这也是Agentic AI系统的基本架构,几乎所有的创企都在采用。

借助英伟达提供的开源模型和工具,开发者现在也可以定制AI系统,并使用最前沿的模型能力。目前,英伟达已经将上述框架整合为“蓝图”,并集成到SaaS平台中去。用户可以借助蓝图实现快速部署。
现场演示的案例中,这一系统系统可以根据用户意图,自动判断任务应由本地私有模型还是云前沿模型处理,也可调用外部工具(如邮件API、机器人控制接口、日历服务等),并实现多模态融合,统一处理文本、语音、图像、机器人传感信号等信息。
这些复杂的能力在过去是绝对无法想象的,但如今已经变得微不足道。在ServiceNow、Snowflake等企业平台上,都能使用到类似的能力。
04.开源Alpha-Mayo模型,让自动驾驶汽车“思考”
英伟达相信物理AI和机器人最终将成为全球最大的消费电子细分市场。所有能够移动的事物,最终都将实现完全自主,由物理AI驱动。
AI已经经历了感知AI、生成式AI、Agentic AI阶段,现在正进入物理AI时代,智能走入真实世界,这些模型能够理解物理规律,并直接从物理世界的感知中生成行动。
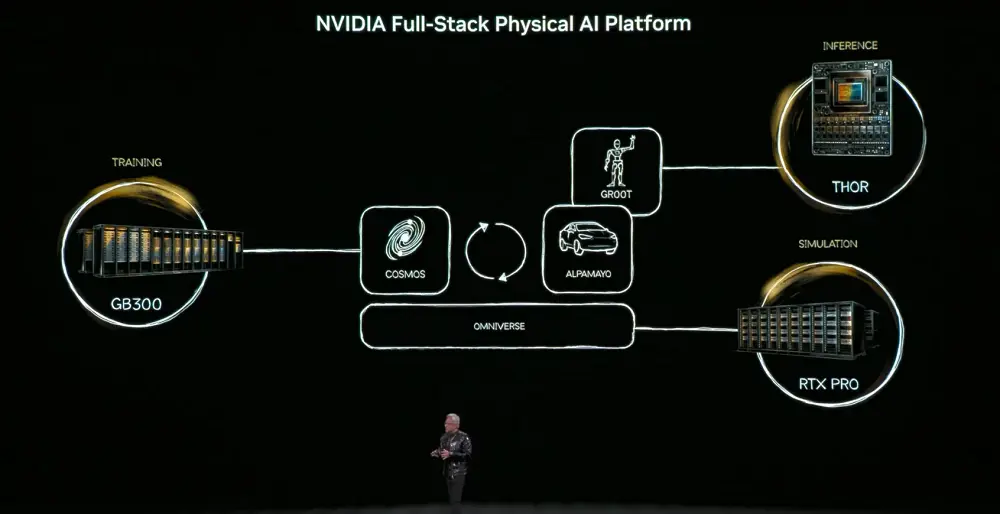
不要要实现这一目标,物理AI必须学会世界的常识——物体恒存、重力、摩擦。这些能力的获取将依赖三台计算机:训练计算机(DGX)用于打造AI模型,推理计算机(机器人/车载芯片)用于实时执行,仿真计算机(Omniverse)用于生成合成数据、验证物理逻辑。
而其中的核心模型是Cosmos世界基础模型,将语言、图像、3D与物理规律对齐,支撑从仿真生成训练数据的全链路。
物理AI将出现在三类实体中:建筑(如工厂、仓库),机器人,自动驾驶汽车。
黄仁勋认为,自动驾驶将成为是物理AI的第一个大规模应用场景。此类系统需要理解现实世界、做出决策并执行动作,对安全性、仿真和数据要求极高。
对此,英伟达发布Alpha-Mayo,一个由开源模型、仿真工具和物理AI数据集组成的完整体系,用于加速安全、基于推理的物理AI开发。
其产品组合为全球车企、供应商、创企和研究人员提供构建L4级自动驾驶系统的基础模块。

Alpha-Mayo这是是业内首个真正让自动驾驶汽车“思考”的模型,这一模型已经开源。它通过将问题拆解为步骤,对所有可能性进行推理,并选择最安全的路径。

这种推理型任务-行动模型使自动驾驶系统能够解决此前从未经历过的复杂边缘场景,例如繁忙路口的交通灯失效。
Alpha-Mayo拥有100亿个参数,规模足以处理自动驾驶任务,同时又足够轻量,可运行在为自动驾驶研究人员打造的工作站上。
它能接收文本、环视摄像头、车辆历史状态和导航输入,并输出行驶轨迹和推理过程,让乘客理解车辆为何采取某个行动。
现场播放的宣传片中,在Alpha-Mayo的驱动下,自动驾驶汽车可以在0介入的情况下自主完成行人避让、预判左转车辆并变道绕开等操作。

黄仁勋称,搭载Alpha-Mayo的梅赛德斯奔驰CLA已经投产,还刚刚被NCAP评为世界上最安全的汽车。每条代码、芯片、系统都经过安全认证。该系统将在美国市场上线,并将在今年晚些时候推出更强驾驶能力,包括高速公路脱手驾驶,以及城市环境下的端到端自动驾驶。

英伟达亦发布了用于训练Alpha-Mayo的部分数据集、开源推理模型评估仿真框架Alpha-Sim。开发者可以使用自有数据对Alpha-Mayo进行微调,也可以使用Cosmos生成合成数据,并在真实数据与合成数据结合的基础上训练和测试自动驾驶应用。除此之外,英伟达宣布NVIDIA DRIVE平台现已投入生产。
英伟达宣布,波士顿动力、Franka Robotics、Surgical手术机器人、LG电子、NEURA、XRLabs、智元机器人等全球机器人领先企业均基于NVIDIA Isaac和GR00T构建。

黄仁勋还官宣了与西门子的最新合作。西门子正将英伟达CUDA-X、AI模型和Omniverse集成到其EDA、CAE和数字孪生工具与平台组合中。物理AI将被广泛用于设计、仿真到生产制造和运营的全流程。
05.结语:左手拥抱开源,右手将硬件系统做到不可替代
随着AI基础设施的重心正从训练转向大规模推理,平台竞争已从单点算力,演进为覆盖芯片、机架、网络与软件的系统工程,目标转向以最低TCO交付最大推理吞吐,AI正进入“工厂化运行”的新阶段。
英伟达非常注重系统级设计,Rubin同时在训练和推理上实现了性能与经济性的提升,并能作为Blackwell的即插即用替代方案,可从Blackwell无缝过渡。
在平台定位上,英伟达依然认为训练至关重要,因为只有快速训练出最先进模型,推理平台才能真正受益,因此在Rubin GPU中引入NVFP4训练,进一步提升性能、降低TCO。
同时,这家AI计算巨头也持续在纵向扩展和横向扩展架构上大幅强化网络通信能力,并将上下文视作关键瓶颈,实现存储、网络、计算的协同设计。
英伟达一边大举开源,另一边正将硬件、互连、系统设计做得越来越“不可替代”,这种持续扩大需求、激励token消耗、推动推理规模化、提供高性价比基础设施的策略闭环,正为英伟达构筑更加坚不可摧的护城河。