


原文作者:Anastasia Matveeva, Gonka 协议联合创始人
在 上一篇文章 中,我们探讨了LLM去中心化推理中安全与性能的根本矛盾。今天,我们将兑现承诺,深入探讨一个核心问题:在一个开放网络中,你如何真正验证某个节点确实运行了它声称的那个精确模型,而没有偷梁换柱?
01. 为什么验证如此困难
要理解验证机制,不妨回顾Transformer在执行推理时的内部过程。当输入令牌被处理时,模型的最后一层会产出logits——即词汇表中每个令牌原始的、未归一化的分数。这些logits随后通过softmax函数转换为概率,从而在所有可能的下一令牌上形成一个概率分布。在每一个生成步骤中,都从此分布中抽样一个令牌,以继续生成序列。
在深入探讨潜在的攻击向量和具体的验证实施方案之前,我们首先需要理解验证本身为何困难。
问题的根源在于GPU的非确定性。即使是相同的模型和输入,在不同的硬件、甚至同一设备上,由于浮点数精度等问题,也可能产生略微不同的输出。
GPU的非确定性使得直接比较输出令牌序列变得没有意义。因此,我们需要审视Transformer的内部计算过程。一个自然的选择是比较输出层,即模型词汇表上的概率分布是否接近。为了确保我们是在比较同一序列的概率分布,我们的验证程序要求验证者必须完全复现执行器所生成的完全相同令牌序列,然后逐个生成步骤地比较这些概率分布。这个过程将产出一个验证存证,用于证明模型的真实性。
然而,概率性也带来了微妙平衡:我们既要惩罚持续作弊者,又要避免误伤那些只是运气不好、产生小概率输出的诚实节点。阈值设得太严,误杀好人;设得太松,放过坏人。
02. 作弊的经济账:收益与风险
潜在收益:诱惑巨大
最直接的攻击是“模型替换”。假设网络部署需要大量算力的Qwen3-32B模型,一个理性节点可能会想:“如果我偷偷运行小得多的Qwen2.5-3B模型,把省下的算力差价装进口袋呢?”
用30亿参数模型冒充320亿参数模型,算力成本可能降低一个数量级。如果你能欺骗验证系统,就相当于你拿着高级算力的报酬,却交付着廉价算力的结果。
更狡猾的攻击者可能会使用量化技术,声称运行FP8精度,但实际上使用的是INT4量化。性能差异可能不那么显著,但成本节约依然可观,并且输出可能足够相似,以至于能通过简单的验证。
在更复杂的层面上,还存在预填充攻击。这种攻击允许攻击者为廉价模型的输出生成证明,仿佛该输出是由网络所期望的完整模型生成的一样。其工作原理如下:
例如,链上达成共识,部署具有特定参数集的Qwen3-235B。
1. 执行器使用Qwen2.5-3B生成序列:`[Hello, world, how, are, you]`。
2. 执行器通过单次推理前向传播,为这些完全相同的令牌计算Qwen3-235B的存证:`[{Hello: 0.9, Hi: 0.05, Hey: 0.05}, ...]`。
3. 执行器提交Qwen3-235B的概率作为证明,声称该推理来自Qwen3-235B。
在这种情况下,概率来自于正确的模型,使得它们看起来是合法的,但实际的序列生成过程成本却低廉得多。由于完整模型在理论上也有可能生成与较小模型相同的输出,因此从验证的角度来看,结果可能看起来完全合法。
潜在损失:代价更高
虽然欺骗系统可能带来相当可观的收益,但潜在的损失也同样巨大。作弊者要解决的真正难题不是通过单次验证,而是长期、系统地逃避检测,使得他们在计算上获得的“折扣”超过网络可能施加的惩罚。
在 Gonka 网络中,我们设计了一套精妙的经济抑制机制:
- 人人都是验证者:每个节点都按权重验证部分网络推理
- 声誉系统:新节点声誉值为0,所有推理都被验证。随着持续诚实参与,声誉增长,验证频率可降至1%
- 惩罚机制:作弊被抓,声誉归零,需要约30天重建
- 纪元结算:在约24小时的纪元内,只要被抓到统计显著次数的作弊,整个纪元的奖励全部没收
这意味着,试图节省50%算力的作弊者,可能反而损失100%的收益。这种“得不偿失”的风险,使得作弊在经济上变得极不划算。我们通过验证机制要解决的问题,并非捕捉每一个有疑问的推理,而是划清一条界线,确保我们能够以足够高的概率持续抓住欺诈者,同时又不损害诚实参与者的声誉。
03. 如何抓住作弊者?三种验证方案
那么,我们如何捕捉这些攻击呢?这个问题可以分为两部分:1) 验证证明中的分布是否接近声称模型所产生的分布;2) 确认输出文本确实是基于所提交的存证生成的。
方案一:概率分布比对(核心基础)
当执行器生成推理输出(例如 `[Hello, world, how, are, you]`)时,他们会记录一个验证存证,其中包含最终输出以及输出序列中每个位置的前K个概率(例如,对于第一个位置是 `[{Hello: 0.9, Hi: 0.05, Hey: 0.05}, ...]`,等等)。验证者随后强制其模型遵循完全相同的令牌序列,并计算每个位置上概率的归一化距离 \( d_i \):

其中 \( p_{\text{artifact},ij} \) 是推理存证中该位置第j个最可能令牌的概率,而 \( p_{\text{validator},ij} \) 是验证者分布中**同一个令牌**的概率。
最终的距离度量是每个令牌距离的平均和:
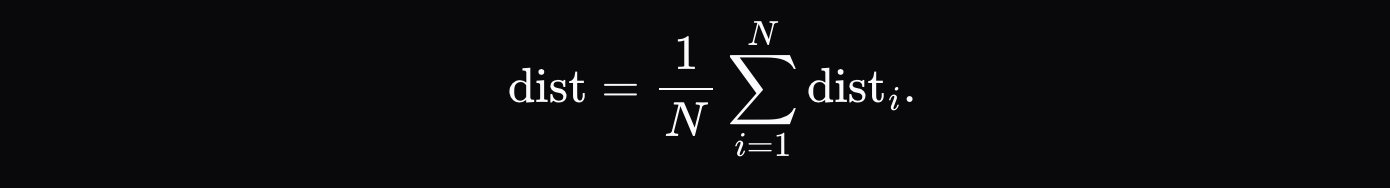
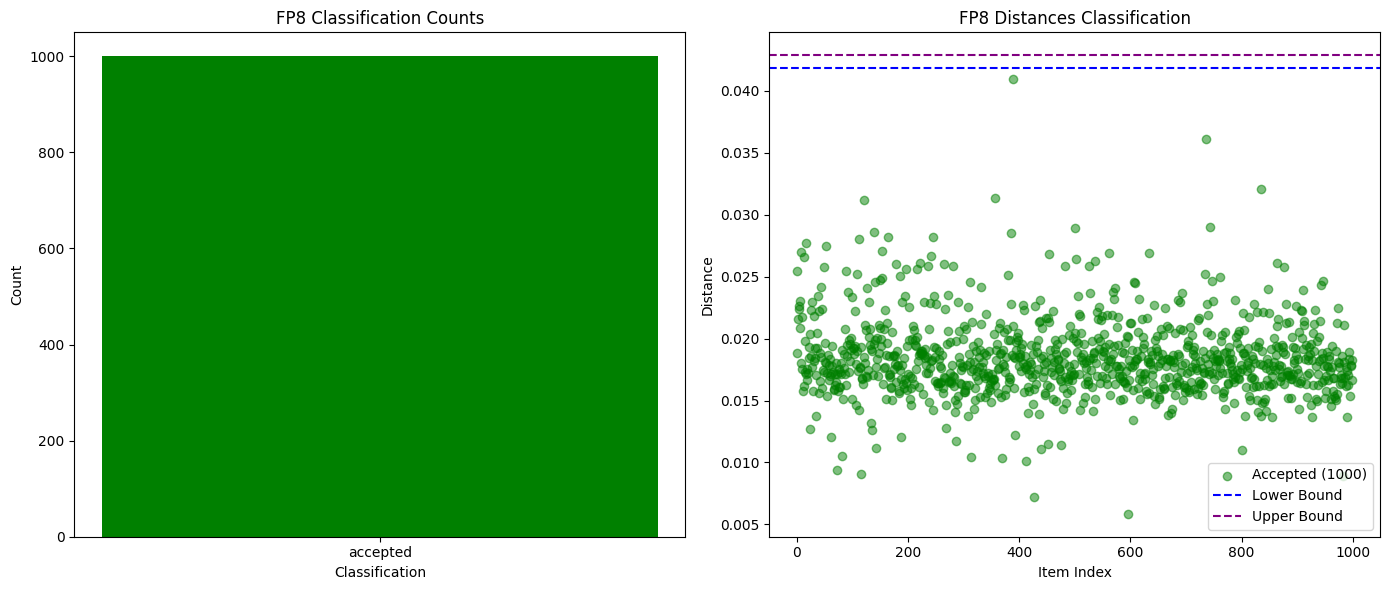
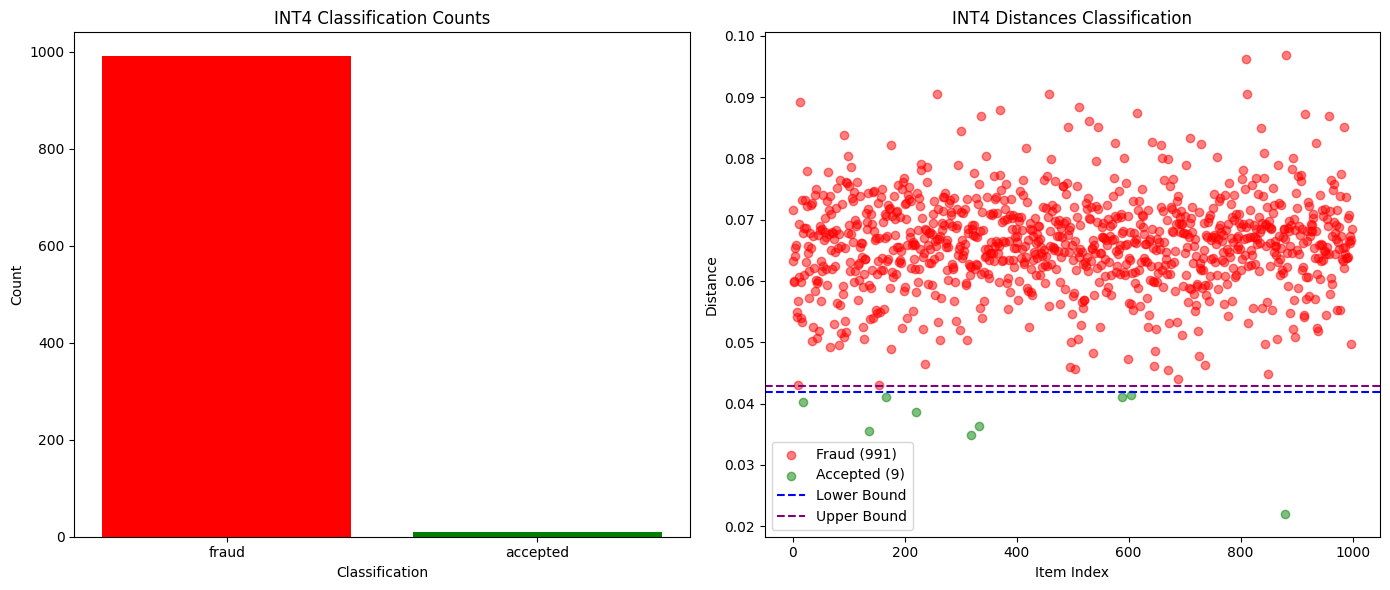
对于捕捉完全不同的模型,甚至是同一模型的不同量化版本,比较前K概率被证明是足够的。如下方的图表所示,当我们在Qwen3-32B FP8与INT4量化版本之间进行测试时,我们实现了99%的欺诈检测率,且零误报。其他模型的概率分布差异也足够大,使得作弊行为能够在一个纪元内被轻松发现,而诚实的参与者则保持安全。
下图为Qwen3-32B FP8 (诚实) vs INT4量化 (欺诈)的成功与失败验证次数对比:
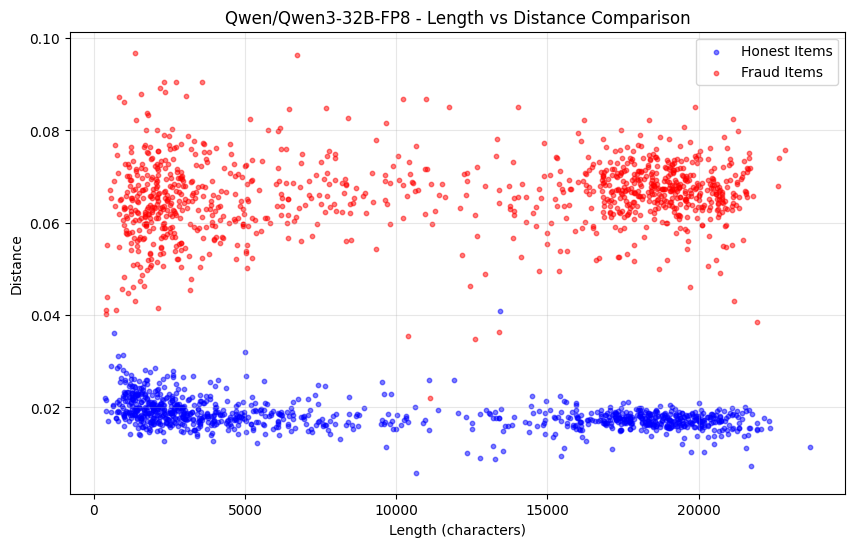
下图为Qwen3-32B FP8 (诚实) vs INT4量化 (欺诈))的概率分布距离随序列长度的变化:
然而,仅靠这种方法的缺点是它无法防范预填充攻击。如果概率确实与完整模型的分布相匹配,但序列是通过一个较小的模型生成的,我们还有几种额外的方法来捕捉这种情况。
方案二:困惑度检测(防御预填充攻击)
除了验证存证是否来自正确模型,我们还检查输出文本是否“可能”来自该存证的概率分布。
如果序列由不同模型生成,其相对于声称模型概率分布的困惑度会异常高。测试中,区分Qwen2.5-7B与Qwen2.5-3B预填充攻击,困惑度差异显著。
捕捉预填充攻击最直观的方法是检查困惑度:除了验证存证是否由声称的模型产生之外,我们还可以检查输出文本**是否很可能**是从提交的分布中生成的:
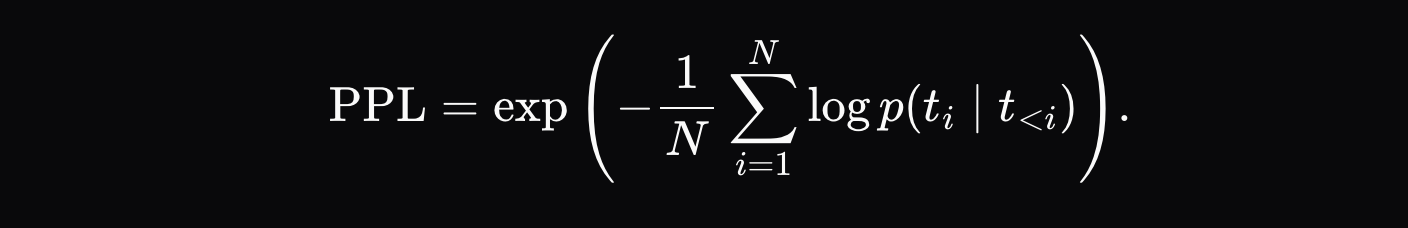
如果困惑度过高,则表明该序列很可能由不同的模型生成。这种方法对于防御使用显著不同模型的攻击效果很好。当我们测试由Qwen2.5-3B生成但声称来自Qwen2.5-7B的序列时,困惑度的差异足够明显,可以设定清晰的阈值。下图显示了一个经过变换的困惑度函数,将其拟合到[0, 1]区间内,其中7B模型的输出大部分落在0.2以下,而预填充攻击的输出(3B模型输出配7B模型概率)全部落在0.4以上。
下图为Qwen2.5-7B (诚实) vs Qwen2.5-3B预填充攻击 (欺诈)变换后的困惑度函数:
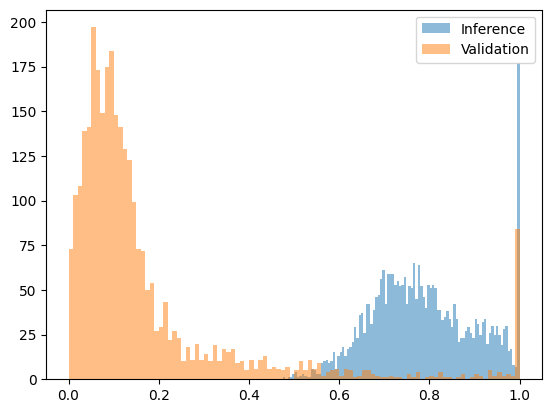
然而,与相似模型以及同一模型的不同量化版本相比,困惑度检测存在局限性。例如,比较Qwen2.5-7B Base的w8a16与w8a8量化版本时,并未显示出明显的差异。
下图为Qwen2.5-7B w8a16 (诚实) vs w8a8量化 (欺诈))变换后的困惑度函数:
好在,使用相似模型进行攻击通常在经济上是没有意义的。如果他们运行一个成本是声称模型70-90%的模型,再加上对真实模型进行一次评分计算,他们实际花费的计算资源可能比老老实实运行真实模型还要多。
需要指出的是,单个由诚实参与者产生的低概率输出不会显著降低其声誉。如果这种低概率输出对于该参与者来说不是持续出现的,即它仅仅是一个偶然的统计离群值,那么他们在纪元结束时仍然会获得全额奖励。
方案三:RNG种子绑定(确定性方案)
这是最彻底的解决方案:将输出序列与随机数生成器种子绑定。
执行器使用源自请求的确定性种子(如`run_seed = SHA256(user_seed || inference_id_from_chain)`)初始化RNG。验证存证包含此种子和概率分布。
验证者使用相同种子验证:如果序列确实来自声称模型的概率分布,必定能复现相同输出。这提供了确定性的“是/否”答案,能彻底杜绝预填充攻击,且验证成本远低于完整推理。
04. 展望:通往去中心化AI的未来
我们分享这些实践与思考,源于对去中心化AI未来的坚定信念。随着AI模型日益渗透社会生活,将模型输出与特定参数绑定的需求只会越来越强。
Gonka 网络选择的验证方案在实践中证明可行,其组件也可复用于其他需要验证AI推理真实性的场景。
去中心化AI不仅是技术的演进,更是生产关系的变革——它试图在开放环境中,用算法和经济机制解决最基本的信任问题。这条路还很长,但我们已迈出坚实的一步。
原文链接


