多模态视频生成技术突破 Web3如何吃到这口红利?



作者:Haotian
除了A本地化“下沉”之外,AI赛道近段时间最大的变化莫过于:多模态视频生成的技术突破了,从原先支持纯文本生成视频演变成文本+图像+音频的全链路整合生成技术。
随便说几个技术突破案例,大家感受下:
1)字节跳动开源EX-4D框架:单目视频秒变自由视角4D内容,用户认可度达到70.7%。也就是说,给一个普通视频,AI能自动生成任意角度的观看效果,这在以前需要专业的3D建模团队才能搞定;
2)百度“绘想”平台:一张图生成10秒视频,宣称可以达到“电影级”质量。但是不是由营销包装夸大的成分,要等8月份的Pro版本更新后实际看效果;
3)Google DeepMind Veo:可以达到4K视频+环境音的同步生成。关键技术亮点是“同步”能力的达成,之前都是视频和音频两套系统拼接,要能做到真正语义层面的匹配需要克服较大的挑战,比如复杂场景下,要做到画面中走路动作和脚步声的对应音画同步问题;
4)抖音ContentV:80亿参数,2.3秒生成1080p视频,成本3.67元/5秒。老实说这个成本控制的还可以,但目前生成质量看,遇到复杂的场景还差强人意;
为什么说这些案例在视频质量、生成成本、应用场景等方面的突破,价值和意义都很大?
1、技术价值突破方面,一个多模态视频生成的复杂度往往是指数级的,单帧图像生成大概10^6个像素点,视频要保证时序连贯性(至少100帧),再加上音频同步(每秒10^4个采样点),还要考虑3D空间一致性。
综合下来,技术复杂度可不低,原本都是一个超大模型硬刚所有任务,据说Sora烧了数万张H100才具备的视频生成能力。现在可以通过模块化分解+大模型分工协作来实现。比如,字节的EX-4D实际上是把复杂任务拆解成:深度估计模块、视角转换模块、时序插值模块、渲染优化模块等等。每个模块专门干一件事,然后通过协调机制配合。
2、成本缩减方面:背后其实推理架构本身的优化,包括分层生成策略,先低分辨率生成骨架再高分辨增强成像内容;缓存复用机制,就是相似场景的复用;动态资源分配,其实就是根据具体内容复杂度调整模型深度。
这样一套优化下来,才会有抖音ContentV的3.67元/5秒的结果。
3、应用冲击方面,传统视频制作是重资产游戏:设备、场地、演员、后期,一个30秒广告片几十万制作费很正常。现在AI把这套流程压缩到prompt+几分钟等待,而且能实现传统拍摄难以达到的视角和特效。
这样一来就把原本视频制作存在的技术和资金门槛变成了创意和审美,可能会促进整个创作者经济的再洗牌。
问题来了,说这么多web2AI技术需求端的变化,和web3AI有啥关系呢?
1、首先,算力需求结构的改变,以前AI拼算力规模,谁有更多同质化的GPU集群谁就赢,但多模态视频生成需求的是多样化的算力组合,对于分布式的闲置算力,以及各个分布式微调模型、算法、推理平台上都可能产生需求;
2、其次,数据标注的需求也会加强,生成一个专业级视频需要:精准的场景描述、参考图像、音频风格、摄像机运动轨迹、光照条件等等都会成为专业的数据标注新需求,用web3的激励方式,可以刺激摄影师、音效师、3D艺术家等提供专业的数据素,用专业垂类的数据标注增强AI视频生成的能力;
3、最后,值得一说的是,当AI从过去集中式大规模资源调配逐渐趋于模块化协作本身就是一种对去中心化平台的新需求,届时算力、数据、模型、激励等共同组合形成自我强化的飞轮,会带动web3AI 和web2AI场景的大融合。

Solana, AVAX, Litecoin, And Remittix Are The Best Altcoins To Buy Now, Claim Experts
Solana, AVAX, and Litecoin stay strong, but Remittix at $0.0987 with $21.4M raised, BitMart listing,...

Morgan Stanley Flips Forecast, Now Sees Fed Rate Cuts in September & December
The post Morgan Stanley Flips Forecast, Now Sees Fed Rate Cuts in September & December appeared firs...
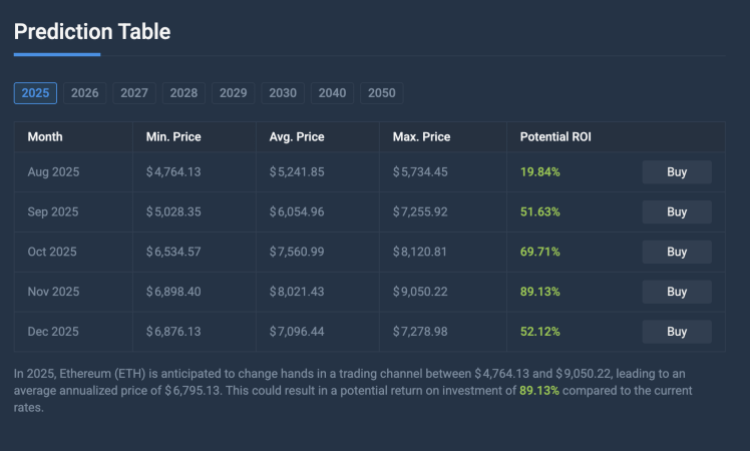
Machine Learning Algorithm Predicts Ethereum Price Will Cross $9,000, Here’s When
After a turbulent four years since the explosive rally of 2021, the Ethereum price looks ready to se...