Felipe
@PhilCrypto77
$GOOGL
@JoshKale
This post got ZERO attention but is BY FAR the biggest AI news this week
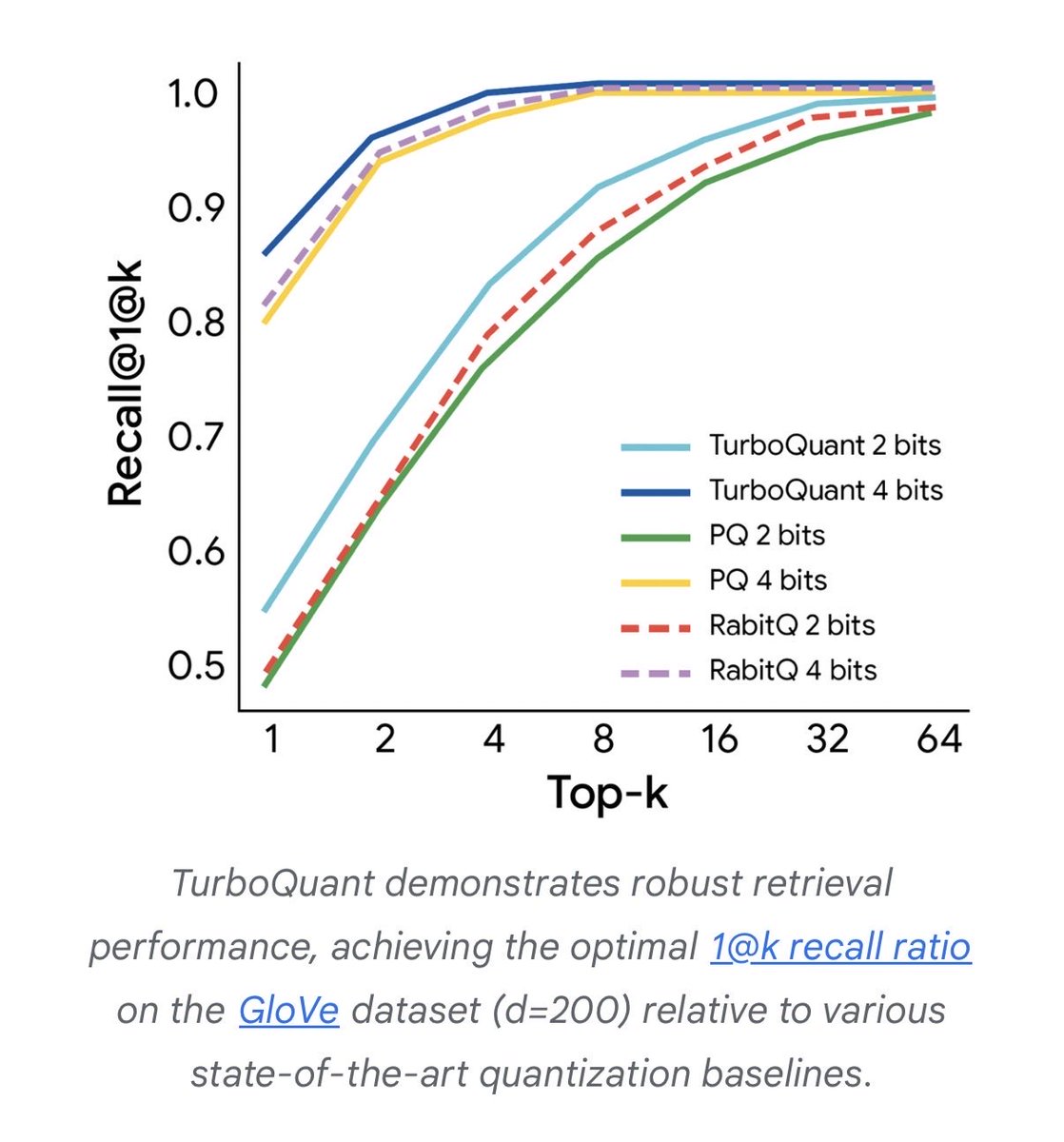
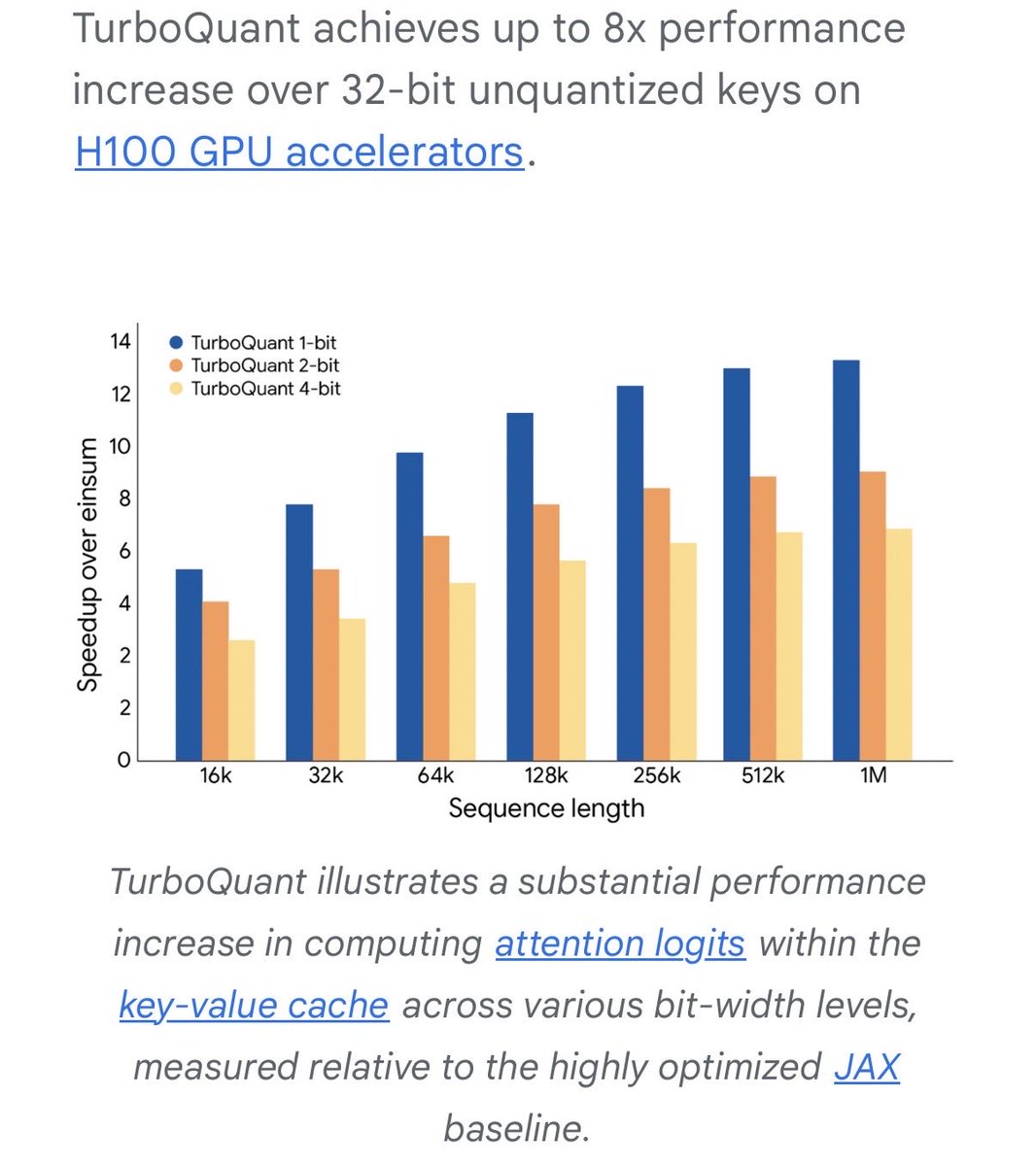
Google just published TurboQuant: a compression algorithm that makes AI inference 8x faster while using 6x less memory. No retraining. No accuracy loss.
The biggest cost is inference which happens billions of times a day, scaling with every user and query. It’s the bill that never stops growing.
Inference also eats memory alive. The reason why GPU memory is the scarcest, most expensive resource in AI.
Previous compression methods had a little secret: shrinking the data required storing extra instructions about how it was shrunk. That overhead ate nearly half the savings. Google found a way to restructure the data so those instructions aren’t needed at all. The overhead just vanishes.
32 bits compressed to 3. The entire cost structure shifts. Context windows expand on existing hardware. API costs compress. Models that needed clusters start fitting on smaller machines.
This seems like a pretty big deal for team google and the industry at large